Claude Code as Orchestrator: One Brain, Many Hands Claude Code làm nhạc trưởng: một bộ não, nhiều đôi tay
Once Codex and AGY can run headless, the real question isn't which agent is best — it's who holds the master plan. A field guide to using Claude Code as the orchestrator and everything else as workers. Khi Codex và AGY đã chạy được headless, câu hỏi thật sự không phải agent nào giỏi nhất — mà ai giữ bản kế hoạch tổng. Cẩm nang dùng Claude Code làm nhạc trưởng, mọi thứ còn lại làm thợ.
Once tools like Codex and AGY can run headless — driven by a script, not a human typing into a chat box — a new question quietly becomes the important one. Not which agent is smartest, but who holds the overall vision. The moment you give one AI a second AI to help, you stop having a tooling problem and start having a management problem.
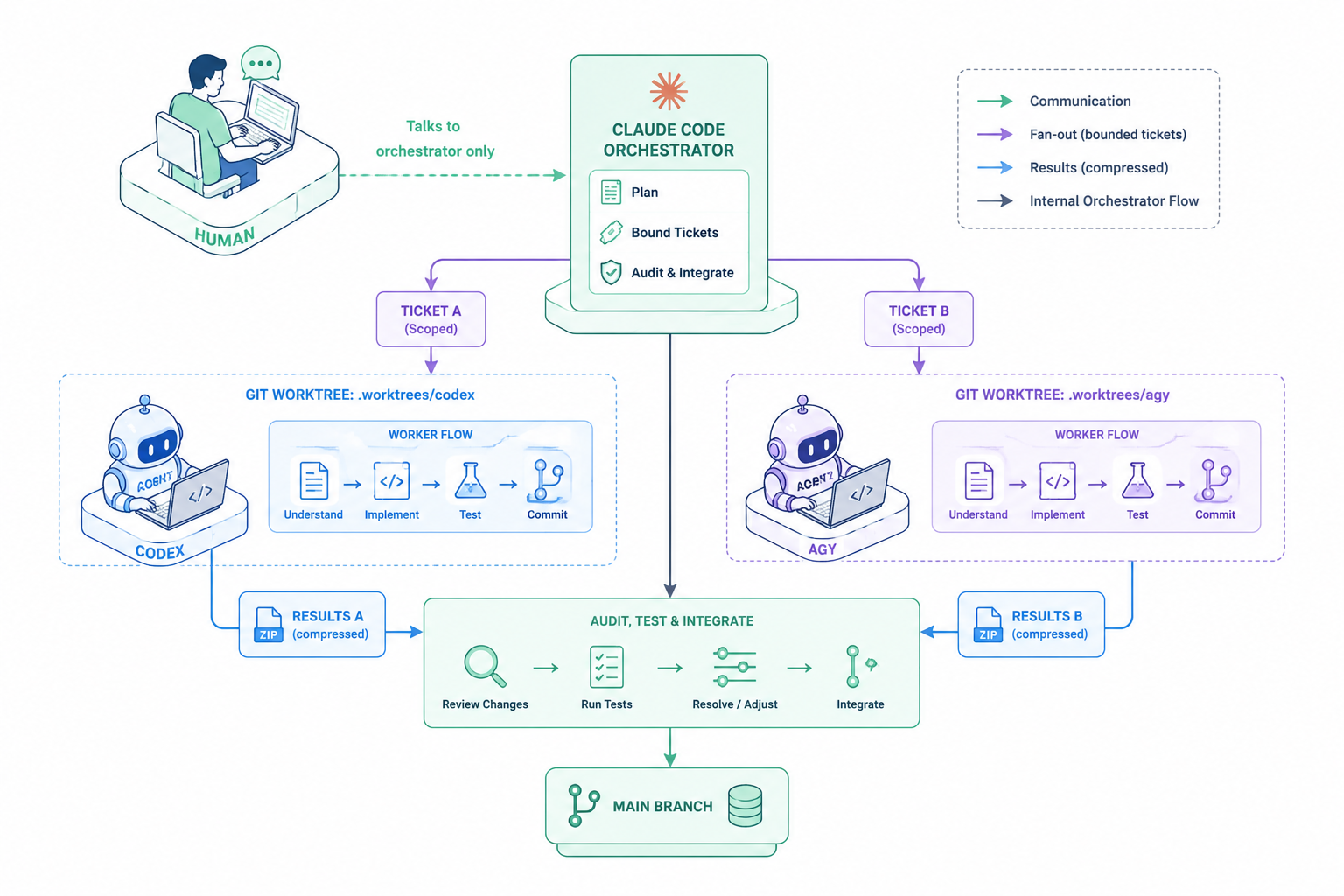
My answer, after living with it for a while: Claude Code is the orchestrator. Everything else is a worker that takes a narrow ticket and goes away.
The general contractor problem
A construction site with many skilled tradespeople only runs well when one person holds the master blueprint. If every crew does its own part and also quietly adjusts the architecture, reshuffles the schedule, and sets its own standards, the project drifts — not dramatically, but in small, compounding ways that are painful to unwind later.
Multiple AI agents on one repo are exactly this site. More agents do not automatically produce a better system. Without a single coordination point, they don't add up — they diverge. The thing that keeps the build coherent isn't raw skill; it's a single point of integration that owns the plan and reconciles the pieces before they harden into conflicts.
One channel, not a switchboard
The operating rule I follow is almost embarrassingly simple: I only talk to Claude Code. I write prompts for Claude Code, I hand it objectives, and I let it decide when to call Codex or AGY. I don't open Codex to type a prompt by hand. I don't open AGY to write a different one.
The failure mode this avoids is becoming a manual router — copying a result out of one window, pasting it into another, holding the state of three branches in your own head. The instant you do that, you are the orchestrator, and you're slower and more forgetful at it than the model is.
Mental model: tech lead and contractor
It helps to name the two roles precisely, because they are genuinely different jobs.
Claude Code is the tech lead. It reads the repo, understands the objective, holds the plan, sees where the risk is, knows what has to be tested, and — crucially — can reject a worker's result that doesn't hold up.
Codex and AGY are contractors. They accept a narrow scope, work inside a sandbox, return a result, and exit. The single most important principle here: a worker should not own the repo. Ownership — the plan, the standards, the final yes/no — stays with the orchestrator.
Why spreading context around fails
The tempting alternative is to give several agents full context windows and let them all edit the same working tree. It breaks in a specific, predictable way:
Agent A changes an abstraction. Agent B is still building on the old one. Agent C writes the docs from some intermediate state that no longer exists.
The conflicts that result aren't merely Git conflicts you can resolve line by line. They're conceptual — three different mental models of the same codebase, all live at once. No merge tool fixes a disagreement about what the code means.
Codex as the code worker
Codex fits code work well for a mechanical reason: codex exec runs headless and script-friendly, with clean output. Run it with --json and it emits a stream of JSONL events — thread.started, turn.started, item.completed, turn.completed — so the orchestrator can track state as structured data instead of parsing prose. The --output-schema flag pushes this further, forcing the result into a shape you define, which kills most of the regex-and-hope parsing. That makes it strong for patches, reviews, extraction, and any structured generation where you want a predictable envelope around the answer.
AGY as the cautious second opinion
AGY here is the Google Antigravity CLI (v1.0.0 — the standalone CLI, not the v2.x desktop app). It runs on its own with a print mode (-p), a directory flag (--add-dir), a continue flag (-c), and OAuth. I treat it as a second opinion — a different perspective on wording, structure, or an alternative read — precisely because it didn't write the thing it's reviewing.
There's a real caveat: its free tier is small (roughly 20 requests a day) and shared with the desktop app, which makes it a bad fit for careless fan-out. Codex sees more frequent use simply because codex exec is cleaner to drive; AGY behaves more like a reviewer whose quota cost forces you to call it on purpose.
A realistic fan-out
Say a task bundles three things: a refactor, some docs, and tests. Here's how it actually plays out:
- Claude Code reads the repo first and identifies the boundaries — what's coupled, what isn't.
- It decides the refactor-plus-tests slice is something Codex can take, and writes a specific worker prompt: which files to read, which to modify, the test criteria, and the expected output (the patch, plus the risks and assumptions it hit).
- The docs slice goes to AGY for wording and structure suggestions.
- Both results come back, and Claude Code does not blindly merge them. This step is the synchronization gate: it reads the diffs, fixes the mismatches, runs the tests, and only then updates the plan. Nothing lands until the tests pass.
The human watched one conversation the whole time.
It's not "three times faster" — it's a cleaner head
It's tempting to sell this as a speed multiplier. That's the wrong pitch. For small tasks, coordination overhead can make it slower. The real benefit is different: Claude Code doesn't have to carry all the side analysis in its main context.
Workers return compressed results — a patch, a few notes, the risks, the assumptions. The orchestrator stays the final decision-maker, but its working memory doesn't get clogged with every worker's intermediate reasoning. On a long task, that's what keeps the session coherent instead of slowly drowning in its own scrollback.
Infrastructure: worktree plus terminal
Parallel agents need parallel workspaces or they overwrite each other. Git worktree is nearly the backbone here: each worker gets its own branch and directory, so patches never clobber one another, and the orchestrator integrates across branches at the end. Pair it with tmux to hold several terminal sessions, keep long-running commands alive, and step back into any worker when you need to. It's an old, boring pattern, and that's the point — separate file space via Git, separate execution space via terminal, let the orchestrator do the joining.
Do you need a fancy UI for this?
Tools like OMX (oh-my-codex) and cmux try to productize the pattern — making multi-agent, multi-terminal work visible and hiding the mechanics of worktree, split, session, and notification. They're interesting, but I'd push back on adopting them reflexively. At the scale of "Claude occasionally calls Codex," a plain setup is plenty. The question of what do you even look at them with only becomes real once several workers are genuinely running in parallel. Buy the dashboard when you have something to put on it.
Cost discipline: the unglamorous part that decides survival
This is the boring section that actually determines whether the workflow lasts. I keep the Claude Code subscription as the always-on orchestrator — the primary place I work — while Codex and AGY are metered worker calls spent with intent. Let an agent call workers in loose exploratory loops and you've built a token-burning machine. Fan-out earns its keep only when the task has clear boundaries, verifiable output, and genuinely takes load off the main context. Otherwise it's spend with no return.
Where this breaks — and how to hold the line
This pattern is hierarchical orchestration, and like any hierarchy it has a few specific failure points worth naming up front rather than discovering the hard way.
The root can poison everything. The orchestrator is a single point of failure. If Claude Code misreads the goal, every worker faithfully executes the wrong thing — the mistake doesn't average out across agents, it multiplies. The mitigation is blunt: spend real effort on the orchestrator's understanding before any fan-out, and have it state the plan back to you, so you can catch a wrong turn while it's still cheap.
The output is probabilistic, so make the gate deterministic. An LLM worker won't return the same thing twice, and it can hand back confident, well-formatted, wrong code. You don't fix that with a nicer prompt — you fix it with the synchronization gate: the orchestrator merges nothing until the integration tests pass. The tests are what convert a probabilistic result into a trustworthy one. No test, no merge.
Workers need a leash, not freedom. The fear that agents will "go rogue" is reasonable, and the answer is guardrails baked into the worker prompt: which files it may touch, what it must not change, the exact shape of the output, and a hard definition of done. A worker isn't set loose on the repo — it's handed a fenced yard and one task. (This is the operational face of a worker should not own the repo.)
Be explicit about the handshake. A worker session has a clear open and close: the orchestrator hands it a bounded ticket, the worker runs in isolation (its own worktree), returns a compressed result, and exits — it doesn't linger holding state. Treat each call as a transaction, not a long-lived conversation. The orchestrator is the only thing that persists across the whole job; workers are summoned, used, and dismissed.
That last point is the real reason to split sessions at all. It's context isolation — keeping one worker's noise out of the orchestrator's working memory — not "every agent for itself." The separation is a discipline, not a free-for-all.
When NOT to orchestrate
The common trap is splitting work just because you can. A one-file bug is often faster for Claude Code to fix directly than to write a worker prompt, wait, read the patch, and merge it. An architectural decision that's still forming should not go to a worker that lacks the full picture — it'll hand back something plausible and subtly misaligned. Keep high-coupling, high-trade-off, and history-dependent work inside the orchestrator's head.
What's actually safe to delegate
Good worker tickets have concrete input, output, and a way to judge them — and don't require the soul of the whole codebase:
- "Read this module and propose the missing test cases."
- "Write a migration for this schema."
- "Scan the docs for API inconsistencies."
- "Extract the action items from these 20 notes as JSON matching this schema."
Each of these is bounded, verifiable, and self-contained. That's the signature of work worth handing off.
Why an agent and not a script?
A fair objection: if the task is "write a migration for this schema," why not a plain script or a CI job? It'd be cheaper, faster, and deterministic. The honest answer is that the line sits exactly there. If a task is fully specifiable — the same input always maps to the same correct output — a script wins, and you should write the script. Don't pay an LLM to do sed's job.
You reach for a worker only when the task needs judgment: reading an unfamiliar module and inferring which test cases are genuinely missing, refactoring across code that doesn't follow one rigid pattern, choosing the least-surprising wording for a doc. Those resist being pinned into if/else. The rule of thumb: if you could write the regex, write the regex. Hand an agent only the part that truly requires reasoning over messy, underspecified context — that's the part a script can't touch, and the only part that justifies the cost.
The real skill is decomposition
The actual skill was never how many agents to call. It's decomposition: knowing what needs full context, what's a narrow ticket, what can run in parallel, and what isn't worth orchestrating at all. Claude Code as orchestrator only works if you give it clear objectives and the authority to integrate. Codex and AGY only work if the worker prompt is specific enough that they don't have to reinvent the context from scratch.
A modest setup, on purpose
I lean toward something deliberately modest: one main orchestrator, a few headless workers, git worktree for parallel work when it's actually needed, and discipline against fan-out that can't justify itself. This doesn't turn development into a perfect autonomous orchestra. It just stops me from shuttling by hand between chat windows.
So when several agents show up on the table, the question worth asking isn't which agent is best. It's: which work actually deserves to be lifted out of the orchestrator's head?
You — by what criteria are you dividing work among your agents?
Khi những công cụ như Codex và AGY đã chạy được headless — điều khiển bằng script chứ không phải con người gõ vào khung chat — một câu hỏi mới âm thầm trở thành câu hỏi quan trọng. Không phải agent nào thông minh nhất, mà ai giữ tầm nhìn tổng thể. Khoảnh khắc bạn giao cho một con AI thêm một con AI nữa để phụ việc, bạn không còn gặp vấn đề công cụ — bạn bắt đầu gặp vấn đề quản lý.
Câu trả lời của mình, sau một thời gian sống cùng nó: Claude Code là nhạc trưởng. Mọi thứ còn lại là người thợ nhận một ticket hẹp rồi biến đi.
Bài toán nhà thầu chính
Một công trường với nhiều thợ giỏi chỉ chạy tốt khi có một người giữ bản vẽ tổng. Nếu mỗi tổ vừa làm phần của mình vừa lẳng lặng chỉnh kiến trúc, xáo lại tiến độ, và tự đặt tiêu chuẩn riêng, dự án sẽ trôi dạt — không kịch tính, mà theo những cách nhỏ tích tụ lại, gỡ ra rất mệt về sau.
Nhiều AI agent trên một repo chính là cái công trường đó. Thêm agent không tự động cho ra một hệ thống tốt hơn. Thiếu một điểm điều phối duy nhất, chúng không cộng lại — chúng phân kỳ. Thứ giữ công trình mạch lạc không phải kỹ năng thô; mà là một điểm tích hợp duy nhất sở hữu bản kế hoạch và hóa giải các mảnh trước khi chúng đông cứng thành xung đột.
Một kênh, không phải tổng đài
Quy tắc vận hành mình theo đơn giản đến mức gần như ngượng: mình chỉ nói chuyện với Claude Code. Mình viết prompt cho Claude Code, giao mục tiêu cho nó, và để nó quyết định khi nào gọi Codex hay AGY. Mình không mở Codex để gõ prompt bằng tay. Mình không mở AGY để viết một prompt khác.
Kiểu hỏng mà điều này tránh được là trở thành một bộ định tuyến thủ công — copy kết quả từ cửa sổ này, dán sang cửa sổ kia, ôm trạng thái của ba cái branch trong đầu mình. Ngay khi bạn làm vậy, bạn chính là nhạc trưởng — và bạn chậm hơn, hay quên hơn model.
Mental model: tech lead và nhà thầu
Nên gọi tên hai vai cho chính xác, vì chúng thật sự là hai công việc khác nhau.
Claude Code là tech lead. Nó đọc repo, hiểu mục tiêu, giữ kế hoạch, thấy rủi ro nằm ở đâu, biết cái gì phải test, và — quan trọng nhất — có thể từ chối kết quả của worker khi nó không trụ được.
Codex và AGY là nhà thầu. Chúng nhận một phạm vi hẹp, làm trong sandbox, trả kết quả, rồi thoát. Nguyên tắc quan trọng nhất ở đây: một worker không nên sở hữu repo. Quyền sở hữu — kế hoạch, tiêu chuẩn, cái gật/lắc cuối cùng — thuộc về nhạc trưởng.
Vì sao rải context ra khắp nơi thì hỏng
Lựa chọn hấp dẫn ngược lại là cho vài agent đầy đủ context window và để tất cả cùng sửa một working tree. Nó hỏng theo một cách rất cụ thể, dễ đoán:
Agent A đổi một abstraction. Agent B vẫn đang xây trên cái cũ. Agent C viết docs từ một trạng thái trung gian không còn tồn tại nữa.
Xung đột sinh ra không chỉ là xung đột Git mà bạn resolve từng dòng. Chúng mang tính khái niệm — ba mental model khác nhau về cùng một codebase, cùng sống một lúc. Không công cụ merge nào sửa được sự bất đồng về việc đoạn code có nghĩa là gì.
Codex làm worker code
Codex hợp với việc code vì một lý do cơ học: codex exec chạy headless, thân thiện với script, output sạch. Chạy nó với --json thì nó phát ra một dòng các event JSONL — thread.started, turn.started, item.completed, turn.completed — để nhạc trưởng theo dõi trạng thái dưới dạng dữ liệu có cấu trúc thay vì đi parse văn xuôi. Cờ --output-schema đẩy xa thêm một bước, ép kết quả vào đúng cái khuôn bạn định nghĩa, dẹp gần hết kiểu parse bằng regex rồi cầu may. Nhờ vậy nó mạnh cho patch, review, trích xuất, và mọi loại sinh có cấu trúc khi bạn muốn một cái "bao bì" đoán trước được quanh câu trả lời.
AGY làm ý kiến thứ hai thận trọng
AGY ở đây là Google Antigravity CLI (v1.0.0 — bản CLI standalone, không phải app desktop v2.x). Nó chạy độc lập với print mode (-p), cờ thư mục (--add-dir), cờ continue (-c), và OAuth. Mình coi nó như một ý kiến thứ hai — góc nhìn khác về câu chữ, cấu trúc, hay một cách đọc khác — chính vì nó không viết ra thứ mà nó đang review.
Có một lưu ý thật: free tier của nó nhỏ (cỡ 20 request/ngày) và dùng chung với app desktop, nên rất dở cho việc fan-out cẩu thả. Codex được dùng thường xuyên hơn đơn giản vì codex exec lái sạch hơn; AGY hành xử giống một reviewer mà cái giá quota buộc bạn phải gọi có chủ đích.
Một lần fan-out thực tế
Giả sử một task gói ba thứ: một cái refactor, ít docs, và test. Đây là cách nó diễn ra thật:
- Claude Code đọc repo trước, và xác định ranh giới — cái gì coupling, cái gì không.
- Nó quyết định mảng refactor-kèm-test là thứ Codex nhận được, và viết một prompt worker cụ thể: đọc file nào, sửa file nào, tiêu chí test, và output mong đợi (patch, kèm rủi ro và giả định nó gặp).
- Mảng docs giao cho AGY để gợi ý câu chữ và cấu trúc.
- Cả hai kết quả quay về, và Claude Code không merge một cách mù quáng. Bước này chính là điểm đồng bộ (synchronization gate): nó đọc diff, sửa chỗ lệch, chạy test, rồi mới cập nhật kế hoạch. Không gì được nhập vào trước khi test xanh.
Con người chỉ nhìn một cuộc hội thoại suốt cả quá trình.
Không phải "nhanh gấp ba" — mà là một cái đầu sạch hơn
Rất dễ rao món này như một hệ số tăng tốc. Đó là cách quảng cáo sai. Với task nhỏ, chi phí điều phối có thể làm nó chậm hơn. Lợi ích thật khác hẳn: Claude Code không phải mang toàn bộ phân tích phụ trong main context.
Worker trả về kết quả đã nén — một patch, vài ghi chú, rủi ro, giả định. Nhạc trưởng vẫn là người ra quyết định cuối, nhưng bộ nhớ làm việc của nó không bị nghẹt bởi mọi suy luận trung gian của từng worker. Với một task dài, đó chính là thứ giữ phiên làm việc mạch lạc thay vì từ từ chết đuối trong chính scrollback của nó.
Hạ tầng: worktree cộng terminal
Agent song song cần workspace song song nếu không chúng ghi đè lên nhau. Git worktree gần như là xương sống ở đây: mỗi worker có branch và thư mục riêng, nên patch không bao giờ đụng nhau, và nhạc trưởng tích hợp giữa các branch ở cuối. Ghép nó với tmux để giữ nhiều phiên terminal, giữ các lệnh chạy lâu sống, và bước trở lại bất kỳ worker nào khi cần. Đây là một pattern cũ, nhàm chán — và đó chính là điểm hay: tách không gian file qua Git, tách không gian thực thi qua terminal, để nhạc trưởng làm phần ghép.
Bạn có cần một UI hào nhoáng cho việc này?
Những công cụ như OMX (oh-my-codex) và cmux cố đóng gói pattern này — làm cho việc multi-agent, multi-terminal trở nên trực quan và giấu đi phần cơ học của worktree, split, session, và thông báo. Chúng thú vị, nhưng mình muốn cản lại việc áp dụng theo phản xạ. Ở quy mô "Claude thi thoảng gọi Codex", một setup trơn là quá đủ. Câu hỏi bạn nhìn chúng bằng cái gì chỉ trở nên thật khi vài worker thật sự chạy song song. Mua cái dashboard khi bạn đã có thứ để bày lên nó.
Kỷ luật chi phí: phần không hào nhoáng nhưng quyết định sống còn
Đây là phần nhàm chán nhưng thật ra quyết định workflow có sống lâu không. Mình giữ subscription Claude Code làm nhạc trưởng always-on — chỗ làm việc chính — còn Codex và AGY là các lời gọi worker có tính phí, tiêu có chủ đích. Để một agent gọi worker trong những vòng lặp thăm dò lỏng lẻo là bạn vừa dựng một cỗ máy đốt token. Fan-out chỉ đáng đồng tiền khi task có ranh giới rõ, output kiểm chứng được, và thật sự gỡ tải khỏi main context. Còn lại thì chỉ là chi mà không thu.
Mô hình này gãy ở đâu — và cách giữ tuyến
Đây là ủy quyền phân cấp (hierarchical orchestration), và như mọi hệ phân cấp, nó có vài điểm gãy cụ thể đáng gọi tên trước, thay vì để tự vấp mới biết.
Cái gốc có thể đầu độc mọi thứ. Nhạc trưởng là một single point of failure. Nếu Claude Code đọc sai mục tiêu, mọi worker sẽ trung thành thực thi cái sai — lỗi không bị trung bình hóa giữa các agent, nó nhân lên. Cách chặn thì thẳng thừng: đầu tư thực sự vào việc nhạc trưởng hiểu đúng trước mọi lần fan-out, và bắt nó trình bày lại kế hoạch cho bạn, để bạn bắt được khúc cua sai khi nó còn rẻ.
Output là xác suất, nên hãy làm cho cửa kiểm tra thành xác định. Một worker LLM không trả về cùng một thứ hai lần, và nó có thể đưa lại đoạn code tự tin, format đẹp, mà sai. Bạn không sửa được bằng prompt hay hơn — bạn sửa bằng điểm đồng bộ: nhạc trưởng không merge gì cho tới khi integration test xanh. Chính các bài test biến một kết quả xác suất (probabilistic) thành một kết quả đáng tin (deterministic). Không test, không merge.
Worker cần dây xích, không phải tự do. Nỗi sợ agent "làm loạn" là chính đáng, và câu trả lời là guardrail nhét sẵn trong prompt worker: được đụng file nào, không được đổi cái gì, output đúng khuôn nào, và một định nghĩa "xong" rạch ròi. Worker không bị thả rông trên repo — nó được giao một cái sân có rào và đúng một task. (Đây là mặt vận hành của nguyên tắc worker không nên sở hữu repo.)
Phải rõ ràng về cái bắt tay (handshake). Một phiên worker có điểm mở và đóng rõ: nhạc trưởng giao cho nó một ticket có giới hạn, worker chạy trong cô lập (worktree riêng), trả về kết quả đã nén, rồi thoát — không nán lại ôm trạng thái. Hãy coi mỗi lời gọi là một giao dịch (transaction), không phải một cuộc hội thoại sống dai. Nhạc trưởng là thứ duy nhất tồn tại xuyên suốt cả công việc; worker được triệu tới, dùng, rồi cho lui.
Điểm cuối đó cũng chính là lý do thật sự để tách session: đó là context isolation — giữ tạp âm của một worker ra khỏi bộ nhớ làm việc của nhạc trưởng — chứ không phải "mạnh ai nấy làm". Sự tách biệt là một kỷ luật, không phải một cái chợ.
Khi nào ĐỪNG điều phối
Cái bẫy phổ biến là tách việc chỉ vì tách được. Một con bug một-file thường để Claude Code tự sửa nhanh hơn là viết prompt worker, chờ, đọc patch, rồi merge. Một quyết định kiến trúc còn đang định hình thì không nên giao cho một worker thiếu toàn cảnh — nó sẽ trả về thứ nghe có lý mà lệch một cách tinh vi. Hãy giữ việc coupling cao, trade-off cao, và phụ thuộc lịch sử ở trong đầu nhạc trưởng.
Cái gì thật sự an toàn để giao đi
Ticket worker tốt có input, output cụ thể và có cách chấm điểm — và không đòi hỏi cái hồn của cả codebase:
- "Đọc module này và đề xuất các test case còn thiếu."
- "Viết một migration cho schema này."
- "Quét docs tìm những chỗ API không nhất quán."
- "Trích action item từ 20 ghi chú này thành JSON khớp schema này."
Mỗi cái đều có giới hạn, kiểm chứng được, và tự chứa. Đó là dấu hiệu của việc đáng giao đi.
Sao không dùng script cho rồi?
Một phản biện hợp lý: nếu task là "viết một migration cho schema này", sao không dùng một script trơn hay một job CI? Rẻ hơn, nhanh hơn, và xác định. Câu trả lời thành thật là ranh giới nằm đúng ngay chỗ đó. Nếu một task có thể đặc tả trọn vẹn — cùng một input luôn cho ra cùng một output đúng — thì script thắng, và bạn nên viết script. Đừng trả tiền cho một LLM để làm việc của sed.
Bạn chỉ với tay tới worker khi task cần phán đoán: đọc một module lạ rồi suy ra những test case nào thật sự còn thiếu, refactor xuyên qua đoạn code không theo một khuôn cứng nào, chọn cách diễn đạt ít gây bất ngờ nhất cho một đoạn docs. Những thứ đó không chịu bị nhốt vào if/else. Nguyên tắc bỏ túi: nếu bạn viết được cái regex, thì viết regex đi. Chỉ giao cho agent đúng cái phần thật sự đòi hỏi suy luận trên ngữ cảnh lộn xộn, đặc tả thiếu — đó là phần script không chạm tới được, và là phần duy nhất biện minh cho chi phí.
Kỹ năng thật là phân rã
Kỹ năng thật chưa bao giờ là gọi bao nhiêu agent. Mà là phân rã (decomposition): biết cái gì cần toàn cảnh, cái gì là ticket hẹp, cái gì chạy song song được, và cái gì không đáng điều phối chút nào. Claude Code làm nhạc trưởng chỉ chạy được nếu bạn cho nó mục tiêu rõ và quyền tích hợp. Codex và AGY chỉ chạy được nếu prompt worker đủ cụ thể để chúng không phải dựng lại context từ đầu.
Một setup khiêm tốn, một cách có chủ đích
Mình nghiêng về một thứ khiêm tốn có chủ đích: một nhạc trưởng chính, vài worker headless, git worktree cho việc song song khi thật sự cần, và kỷ luật chống lại fan-out không tự biện minh được. Cái này không biến phát triển phần mềm thành một dàn nhạc tự hành hoàn hảo. Nó chỉ giúp mình thôi phải chạy tay qua lại giữa các cửa sổ chat.
Nên khi vài agent xuất hiện trên bàn, câu hỏi đáng hỏi không phải agent nào giỏi nhất. Mà là: việc nào thật sự đáng được nhấc ra khỏi đầu nhạc trưởng?
Còn bạn — bạn đang chia việc cho các agent theo tiêu chí gì?